Share
Share
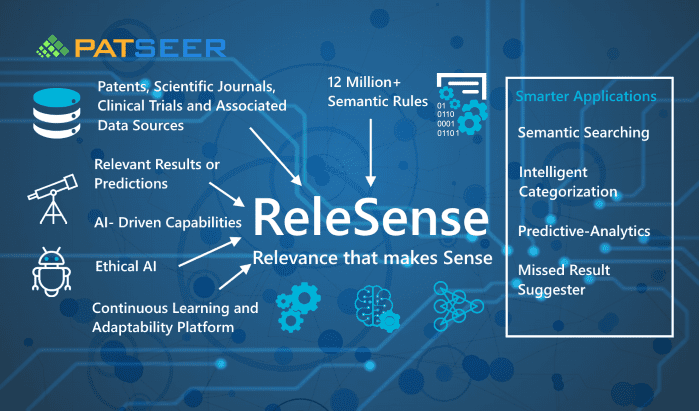
ReleSense™ – An AI-driven NLP engine built
for patent and scientific literature
ReleSense – Semantic Patent Search and Analysis Engine trained over Patent and Scientific Literature
ReleSense™ is PatSeer’s NLP text processing engine that has been trained over patent and scientific literature. With more than 12 million+ semantic rules, the engine is continuously learning from publicly available patents, scientific journals, clinical trials and associated data sources. The engine will power a range of AI driven capabilities in PatSeer beginning from search to categorization, predictive-analytics and via APIs it will empower complementary IP solutions.
Relevance that makes Sense
ReleSense has been coined from the phrase “Relevance that makes Sense” and its core purpose is to provide relevant results and predictions to the end user. To achieve this, ReleSense has been trained to understand patent terminologies and appropriately interpret deep contextualized meanings within patents and scientific literature.
Bringing power of Artificial Intelligence to Patent Search and Analysis
ReleSense solve the more complex (yet real) search related challenges with the power of Artificial Intelligence infused new capabilities such as Semantic Searching, AI assisted Boolean search, Intelligence categorization, Predictive analytics.
Continuous Learning Platform
As newer technologies keep getting discovered, Search scenario keeps changing over time, the interpretations of scientific terms keep evolving over time and so as the semantics of the data. ReleSense leverages a continuous learning platform and constantly learns from new patent filings and additional sources thereby improving its knowledge over time. It continuously enhances with more and more semantic rules and newer training datasets from different fields of science.
User Privacy with Ethical AI
Respecting the sensitivity of user’s data, ReleSense leverages ethical AI and does not use any user provided data such as search queries, annotations or behavior tracking to improve its predictions.
What’s Next in ReleSense
To tackle the volume and complexity of IP information coming in the future, smarter search and text mining capabilities are being built by leveraging the semantic knowledge of ReleSense™. As ReleSense rapidly consumes more information we expect to double the number of semantic rules it has within the next 3 months.